The Case for Unidirectionality
In this post, I will be discussing the benefits of a unidirectional flow of control architectures and how they can be applied to the Model-View-Presenter pattern.
Unidirectional Flow of Control
Unidirectional dataflow is a software architecture pattern that is based on the idea that data should only flow in one direction. This means that data should only be able to flow from the source to the destination, and not the other way around.
In the context of software development, Flow of control refers to the order in which the different parts of a system are executed. In a unidirectional flow of control architecture, the flow of control is unidirectional, meaning that the flow of control only goes in one direction (duh!). This means that the flow of control should only be able to flow from the source to the destination, and not the other way around.
The idea behind unidirectionality is to establish a clear and predictable flow of data within a system, which can make it easier to understand how the system works and to identify and fix any problems that may arise.
This pattern is often used in combination with functional-programming concepts, such as immutable data and pure functions, which can help to further simplify the flow of data within a system.
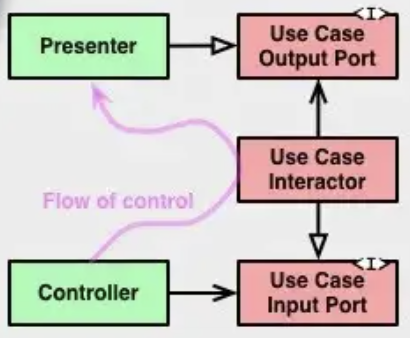
This diagram from Robert C. Martin's book Clean Architecture shows how communication happens:
Let us take a look at how we can apply unidirectional dataflow to the Model-View-Presenter pattern.
protocol UseCaseInput {
func execute()
}
protocol UseCaseOutput {
func didFetchInformation(_ information: Info)
func onErrorFetchingInformation()
}
class UseCaseInteractor: UseCaseInput {
let output: UseCaseOutput
func execute() {
output.didFetchInformation(Info(message: "hello world"))
}
}
class ViewController {
let useCase: UseCaseInput
func viewDidLoad() {
super.viewDidLoad()
useCase.execute()
}
}
extension ViewController: PresenterView {
func showInformation(message: String) { /* Update the UI */ }
func showError(message: String) { /* Update the UI */ }
}
class Presenter: UseCaseOutput {
weak var view: PresenterView?
func didFetchInformation(_ information: Info) {
view?.showInformation(message: information.message)
}
func onErrorFetchingInformation() {
view?.showError(message: "Error fetching")
}
}
Now we just need to compose all components together like so:
let presenter = Presenter()
let interactor = UseCaseInteractor(output: presenter)
let viewController = ViewController(useCase: interactor)
presenter.view = viewController
Against the Bidirectional approach
Let's now compare it with a bidirectional flow approach to MVP, which I think is the most common way I've seen implemented in many companies but also many blogs.
class ViewController {
let presenter: PresenterProtocol
func viewDidLoad() {
super.viewDidLoad()
presenter.onViewDidLoad()
}
}
protocol UseCaseInput {
func getInformation() throws -> Info
}
protocol PresenterProtocol {
func onViewDidLoad()
}
class Presenter: PresenterProtocol {
weak var view: PresenterView?
let useCase: UseCaseInput
func onViewDidLoad() {
do {
try let info = useCase.execute()
view?.showInformation(message: info.message)
} catch {
view?.showInformation(message: "Error fetching")
}
}
}
Composing the above looks like this now:
let presenter = Presenter(useCase: UseCaseInteractor())
let viewController = ViewController(presenter: presenter)
presenter.view = viewController
The bidirectional approach is simpler and easier to understand in simple examples. However, it has some problems that can become more apparent as the system becomes more complex. One main problem is that the presenter is responsible for more tasks than it should be, including transforming domain data into a presentable format, getting that data by calling the use case, and handling error cases that the interactor can throw. This makes it more difficult to test and reuse the presenter in different use cases, and it limits the composability of the system.
SOLID Principles
We can use the unidirectionality of the data flow to help us to follow the SOLID principles. The SOLID principles are a set of design principles that help us to write better code. They are:
- Single Responsibility Principle (SRP)
- Open-Closed Principle (OCP)
- Liskov Substitution Principle (LSP)
- Interface Segregation Principle (ISP)
- Dependency Inversion Principle (DIP)
We all know them by name, but it can be a bit obscure to understand how to bring them from the abstract wording of the books, into our real-life codebases. I think that the unidirectional dataflow can help us to understand how to apply them in practice, by leveraging other patterns like the Composer, Composition Root and Decorators.
Let's say we want to log in to an Analytics service every time we show an error to the user. Implementing this is super easy if we use the Decorator pattern to wrap the calls to the view, but without the presenter even knowing that we're doing such a thing.
class ErrorTrackerPresenterViewDecorator: PresenterView {
let analytics: Analytics
let decoratee: PresenterView
func showError(message: String) {
analytics.logError(message)
decoratee.showError(message: message)
}
func showInformation(message: String) {
decoratee.showInformation(message: message)
}
}
Now we can just compose the Presenter with the ErrorTrackerPresenterViewDecorator and we're done.
let presenter = Presenter()
let interactor = UseCaseInteractor(output: presenter)
let viewController = ViewController(useCase: interactor)
let errorTracker = ErrorTrackerPresenterViewDecorator(
analytics: Analytics(),
decoratee: viewController
)
presenter.view = errorTracker
On the Use Cases
The use cases are the most important part of the system. They are the ones that contain the business logic of the system.
By making the Use Cases follow unidirectionality as well, we've unlocked their potential to model the domain in more specific ways. This is because when the use cases are unidirectional, there's no longer a need to just return a value and/or throw an error, but they can be more specific about what was the result of such business operation.
Let's take a look at how we can model a use case that fetches a list of items from a repository, sorts, and filters the results, and then produces an output.
protocol ProductsUseCaseOutput {
func didFetch(products: [Product])
func notEnoughAvailableProducts()
func didFetchEmptyProductsList()
func didFailFetchingProducts()
}
class ProductsUseCaseInteractor {
let output: ProductsUseCaseOutput
let repository: ProductsRepository
func execute() {
do {
let products = try repository.getAll()
if products.isEmpty {
output.didFetchEmptyProductsList()
return
}
let sortedProducts = products
.sorted(by: { $0.relevancyScore > $1.relevancyScore })
.filter(\.isAvailable)
if sortedProducts.count < 3 {
output.notEnoughAvailableProducts()
return
}
output.didFetch(products: sortedProducts)
} catch {
output.didFailFetchingProducts()
}
}
}
class ProductsListPresenter: ProductsUseCaseOutput {
weak var view: ProductsListView?
func didFetch(products: [Product]) {
view?.showProducts(products.map(ProductViewModel.init))
}
func notEnoughAvailableProducts() {
view?.showMessage("Not enough products")
}
func didFetchEmptyProductsList() {
view?.showMessage("No products matching the search")
}
func didFailFetchingProducts() {
view?.showMessage("Ups, try again later!")
}
}
Compared to when it was the presenter that called the use case and handled errors, this is now contained in the business logic, which makes it easier to test and reuse, but also makes it clear that the decision if outputting an event when there are not enough products is a decision taken by a domain component, representing our business in the exact way we want because we're not limited to just returning one value or throwing a generic Error (that we would need to typecast later on to know what happened and we could lose visibility of the different errors), rather than just a presentation occurrence. It is worth mentioning that not everything had to even be an error in the first place but rather just a business contemplated event.
Also, the presenter is now just a simple mapper that just transforms the results into a view-representable format.
Closing words
As someone who has worked with both unidirectional and bidirectional flow of control architectures, I can attest to the benefits of the former. In a unidirectional flow of control system, data is only allowed to flow in one direction, from the source to the destination. This can make it easier to understand how the system works and to identify and fix any problems that may arise.
On the other hand, the bidirectional approach, while simpler at first, can become problematic as the system becomes more complex. That's why I believe it's worth considering the unidirectional flow of control, especially when working in apps that are composed of multiple developers and even more when there are multiple teams.
I hope this has given you a good understanding of the advantages of the unidirectional flow of control and how it can be applied to achieve a clean architecture. It's a powerful tool to have in your software development toolkit, and I encourage you will consider using it in your projects.